Visual Annotations, Web Annotation and Tagging
Integration with Open Source annotation tool Hypothesis
The integrated Open Source visual annotation tool Hypothesis provides an powerful visual user interface for (collaborative) web annotation and tagging by human editors, teams and groups that supports not only to tag documents and add page notes, but allows you to annotate documents and web pages within the text, even for single words, names, parts of sentences, sentences or paragraphs.
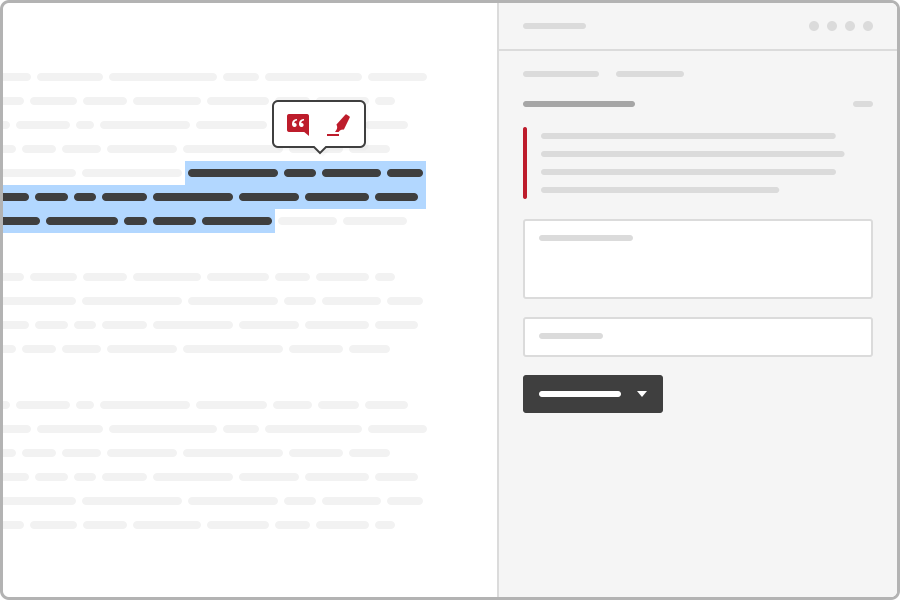
To improve search, textanalytics & textmining and connect knowledge by annotations of human editors, the open source search engine offers an easy to use web user interface for setup an import and indexing of hypothesis annotations, tags and documents.
Why (collaborative) tagging and (collaborative) annotations by (teams of) human editors?
If a name and no of its aliases or a word and no of its synonyms is not contained in the document content or metadata it can not be found. But that doesn't mean, that the document or web page is not important for this topic.
Even if text mining and text analytics technology like automatic named entity recognition of persons, organizations or places and interactive filters and automatic topic detection by thesaurus for automatic content analysis is very helpful to automate much of the researcher(s) and editor(s) work, no automatic text analysis, OCR, automatic tagging of topics or concepts by thesaurus and no machine learning mode is perfect and computers are dumb or/and often have to few data about all context to judge about ambigous data or meaning of texts.
So additionally to automatic text analysis, good search results needs manual annotations by human editors or together in teams to improve of search results, find important and relevant documents, for easier filtering, verification and classification and together connect different knowledge of (interdisciplinary) teams.
Search finds more by combining / data enrichment of content with tags and annotations
If you tag a document or web page with a tag (f.e. a name of a person, organization, location or a concept or word), this document will be found on further queries with this word(s) even if this word(s) is/are not contained in the document or would be not recognized by automatic text analysis.